Model¶
DepthDif uses a conditional pixel-space diffusion model implemented in src/depth_recon/models/diffusion/PixelDiffusion.py.
Model schema:
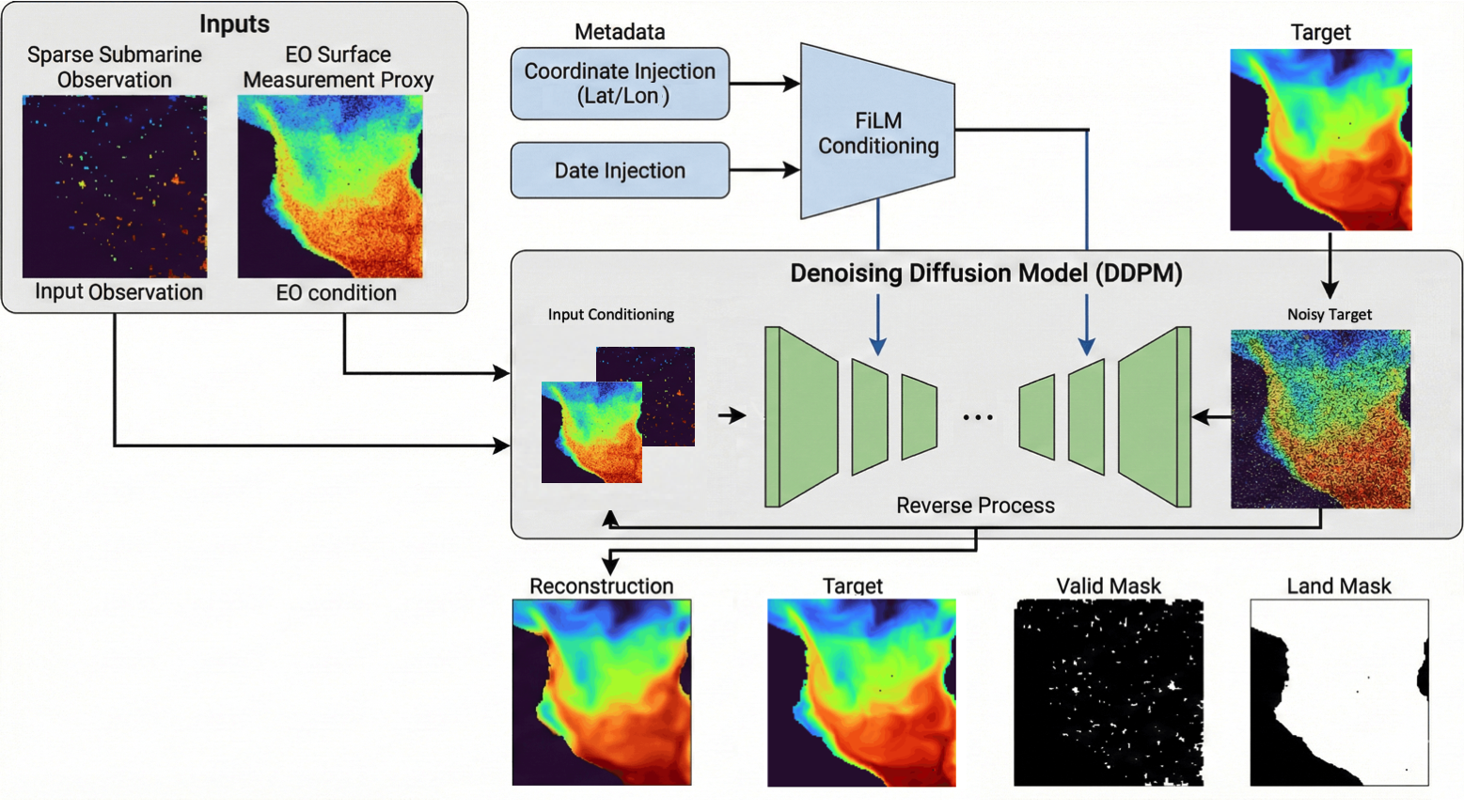
Core stack:
- Lightning wrapper: PixelDiffusionConditional
- diffusion core: DenoisingDiffusionConditionalProcess
- denoiser backbone: UnetConvNextBlock (ConvNeXt-style U-Net)
The model learns to generate y while conditioning on observed channels (x), optional eo, ARGO observation support (x_valid_mask), and GLORYS spatial support (land_mask).
The baseline package in src/depth_recon/models/baselines/ provides non-diffusion comparison models that share the same Lightning predict_step output contract. See Baselines for the IDW and point-wise LSTM implementations, including their input features, no-ARGO behavior, training steps, and inference contract.
Conditioning Setup¶
Three conditioning layouts are selected by the pixel scenario resolver:
- Temperature task:
[OSTIA analysed_sst, x, x_valid_mask, land_mask] -> y - Salinity task:
[SSS sos, x_salinity, x_salinity_valid_mask, land_mask] -> y_salinity - Joint temperature/salinity task:
[OSTIA analysed_sst, cat(x, x_salinity), collapsed x_valid_mask, land_mask] -> cat(y, y_salinity)when--scenario jointis selected.
Condition assembly happens in _prepare_condition_for_model:
- optionally prepend eo (condition_include_eo=true)
- append data channels from x
- optionally append ARGO observation-support x_valid_mask channels (condition_use_valid_mask=true)
- optionally append GLORYS spatial-support land_mask (condition_use_land_mask=true)
- enforce channel count equals model.condition_channels
Architecture Summary¶
UnetConvNextBlock follows a U-Net encoder/decoder with ConvNeXt blocks and linear attention.
With default dim_mults=[1,2,4,8]:
- 4 downsampling stages
- bottleneck block with attention
- 3 upsampling stages with skip connections
- final ConvNeXt block + 1x1 output conv to generated_channels
For the ambient EO preset in src/depth_recon/configs/px_space/training_super_config.yaml, the U-Net base width is dim: 64. This keeps the same depth (dim_mults=[1,2,4,8]) while matching the current 50 generated channels + 53 condition channels.
Time conditioning: - sinusoidal timestep embedding -> MLP -> additive bias in ConvNeXt blocks
Coordinate/date conditioning (when enabled): - per-channel FiLM scale/shift in ConvNeXt blocks - details in Data + Coordinate Injection
Training Objective¶
Training step (training_step) calls conditional diffusion p_loss on normalized model-output tensors. By default this is temperature only; joint mode stacks normalized temperature and salinity channels before loss computation. The dataset still returns temperature and salinity as separate keys; stacking is owned by PixelDiffusionConditional.
Behavior:
- sample random timestep t
- forward diffuse the selected training target to the noisy target branch
- predict either:
- noise (epsilon parameterization), or
- clean sample (x0 parameterization)
Loss options:
- unmasked MSE (default behavior when masking disabled)
- masked MSE with mode-specific supervision support:
- standard mode: over y_valid_mask intersected with GLORYS land_mask on the full y target
- ambient mode: over x_valid_mask intersected with y_valid_mask and GLORYS land_mask on the degraded x target
- the common on-disk mask is not loaded by train/validation dataloaders; optional output_land_mask is only final prediction cleanup support
Ambient occlusion objective (model.ambient_occlusion.enabled: true):
- sample an additional Bernoulli keep-mask over already observed pixels (~A = B * A)
- feed the model a further-corrupted condition (x_tilde = x * ~A) and ~A as condition mask
- switch the diffusion target from y to the original sparse-observation tensor x
- optionally apply ~A to noisy target branch during p_loss (~A * x_t)
- compute masked MSE on the originally valid x support intersected with valid y support and GLORYS land_mask (A ∩ Y ∩ land_mask, not ~A)
- detailed walkthrough and citation: Ambient Occlusion Objective
Current EO config (src/depth_recon/configs/px_space/training_super_config.yaml) uses:
- parameterization: "x0"
- mask_loss_with_valid_pixels: true
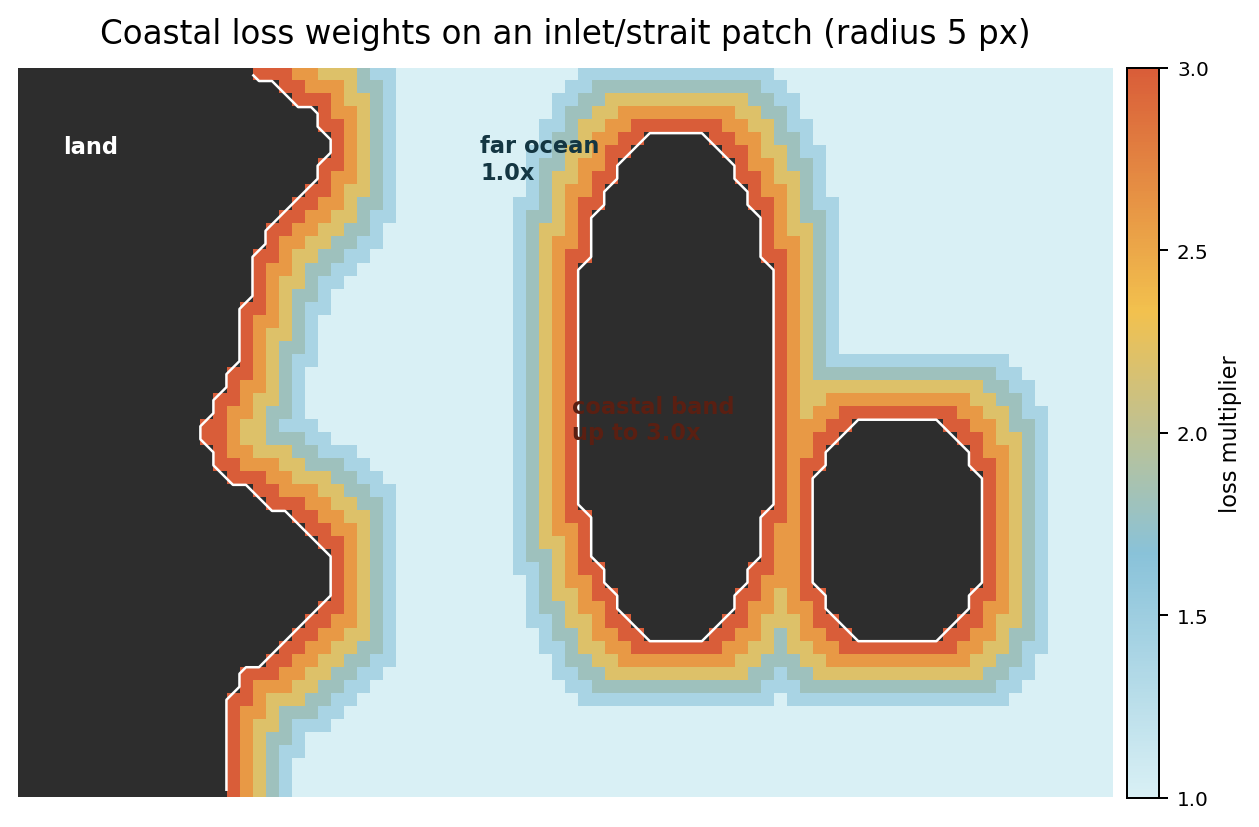
- coastal_loss.enabled: true with radius_px: 5, weight: 3.0, and ramp: linear
Coastal Loss Weighting For Finetuning¶
Hard-area finetuning can additionally emphasize supervised ocean pixels near land through model.coastal_loss.*. The loss still ignores invalid target cells and land cells first; the coastal multiplier is applied only to the remaining supervised ocean support. Far-ocean pixels keep weight 1.0, while ocean pixels close to land ramp up to the configured maximum weight.
Scenario-Selected Temperature And Salinity Modes¶
Pixel training and inference use --scenario temperature|salinity|joint or the top-level scenario key in the super-config. The resolver derives the coupled data/model contract before datasets and models are built:
| Scenario | Output fields | Salinity data | Generated channels | Condition channels |
|---|---|---|---|---|
temperature |
['temperature'] |
disabled | 50 |
53 |
salinity |
['salinity'] |
enabled | 50 |
53 |
joint |
['temperature', 'salinity'] |
enabled | 100 |
103 |
For salinity, the dataloader returns only x_salinity, y_salinity, and their salinity masks, which become the single model-facing field. For joint, PixelDiffusionConditional stacks temperature first and salinity second. Existing 50-channel temperature checkpoints are not shape-compatible with joint 100-channel runs.
Inside the model path, _prepare_model_batch_tensors builds:
x_model = cat([x, x_salinity], dim=1)
y_model = cat([y, y_salinity], dim=1)
x_valid_mask_model = cat([x_valid_mask, x_salinity_valid_mask], dim=1)
y_valid_mask_model = cat([y_valid_mask, y_salinity_valid_mask], dim=1)
The diffusion core remains channel-agnostic and sees one 100-channel normalized
target. The loss is the existing unweighted diffusion MSE over the stacked
normalized channels, masked by the stacked task-valid support intersected with GLORYS land_mask when mask-based
loss is enabled. predict_step splits sampled outputs back into temperature and
salinity fields and denormalizes them with their own normalization helpers.
For non-ambient training, the loss is pulled over all valid target pixels via
y_valid_mask ∩ land_mask, or the stacked target-valid mask intersected with land_mask in joint temperature/salinity mode.
Latent model workflow is configured via src/depth_recon/configs/lat_space/model_config.yaml with AE controls in src/depth_recon/configs/lat_space/ae_config.yaml; see Autoencoder + Latent Diffusion for the full setup.
EMA weight averaging can be enabled through model.ema; see Exponential Moving Average Weights for the implementation details, validation logging behavior, and metric definitions.
Inference Flow¶
Prediction entry point is predict_step.
At inference:
- build condition tensor from batch inputs
- start reverse process from Gaussian latent
- keep condition fixed during reverse sampling
- use configured sampler (ddpm by default, ddim optional)
- optional known-pixel clamping can overwrite known pixels each step
Output dictionary from predict_step:
- y_hat: normalized model output; stacked in joint mode
- y_hat_denorm: denormalized active single field for single-field scenarios, or temperature for joint mode
- y_hat_temperature / y_hat_salinity: normalized field-specific outputs when that field is active
- y_hat_temperature_denorm / y_hat_salinity_denorm: Celsius and PSU field-specific denormalized outputs when that field is active
- denoise_samples: optional intermediate reverse samples
- x0_denoise_samples: optional per-step x0 predictions
- sampler: sampler object used
Uncertainty entry point is uncertainty_step(batch, batch_idx=0, num_samples=20). It runs repeated predictions with intermediates disabled, computes the pixel-wise standard deviation in denormalized physical units, collapses output/depth channels to B x 1 x H x W, and returns uncertainty-only outputs:
- uncertainty: active single field, or temperature in joint mode
- uncertainty_normalized: 0-1 min-max normalized uncertainty raster for display
- uncertainty_temperature / uncertainty_salinity: field-specific uncertainty maps when active
- uncertainty_temperature_normalized / uncertainty_salinity_normalized: field-specific display maps when active
- uncertainty_num_samples, uncertainty_stat, sampler, and further_valid_mask
Post-Processing in Lightning Inference¶
After denormalization, inference can apply:
- optional Gaussian blur (model.post_process.gaussian_blur.*)
- direct y prediction: keep the generated field and set y_valid_mask==0 pixels to NaN
- ambient x completion: return the model prediction as-is after optional sampler-time clamp_known_pixels, then set y_valid_mask==0 pixels to NaN
This post-processing is centralized in predict_step.
Validation Diagnostics¶
Validation computes two paths:
- per-batch validation loss (validation_step) using the same objective as training
- one full reverse-diffusion reconstruction per validation run from the global-rank-0 cached first validation batch (on_validation_epoch_end)
When available, full reconstruction logging includes:
- MSE
- PSNR/SSIM (if skimage is installed)
- qualitative reconstruction grid
- denoising-intermediate grid and MAE-vs-step curve (when intermediates enabled)
- reconstruction plotting keeps the unmerged model prediction panel and masks invalid output support through y_valid_mask
- joint mode logs a separate salinity reconstruction grid under val_salinity_imgs and separate per-band PSU L1 charts under val_salinity_absolute_band_error using a blue-to-green color scale
- these epoch-end diagnostics stay rank-local on global rank 0 to avoid DDP logging mismatches for optional metrics like PSNR/SSIM