Ambient Occlusion Objective in DepthDif¶
This document describes changes implemented to go from the standard DepthDif and the occlusion branch to a re-implementation of the Ambient Diffusion training objective from:
- Daras et al., Ambient Diffusion: Learning Clean Distributions from Corrupted Data (arXiv:2305.19256). Paper: https://arxiv.org/abs/2305.19256
TL;DR¶
Before this change, the model saw one masked input and trained mostly on the pixels that were already missing.
Now, during training only, we do one extra step: we hide some of the still-visible pixels again at random. So the model gets a harder, more incomplete input.
The important part is the loss target: ambient mode now scores the model on the degraded x target only where the input is actually valid and the GLORYS depth support is valid.
Why this matters: it avoids a weak objective where the model can learn shortcuts from the currently visible subset, and instead teaches it to recover stable structure under extra random occlusion.
Inference/sampling did not change. This is a training-objective change only.
Visual Walkthrough¶
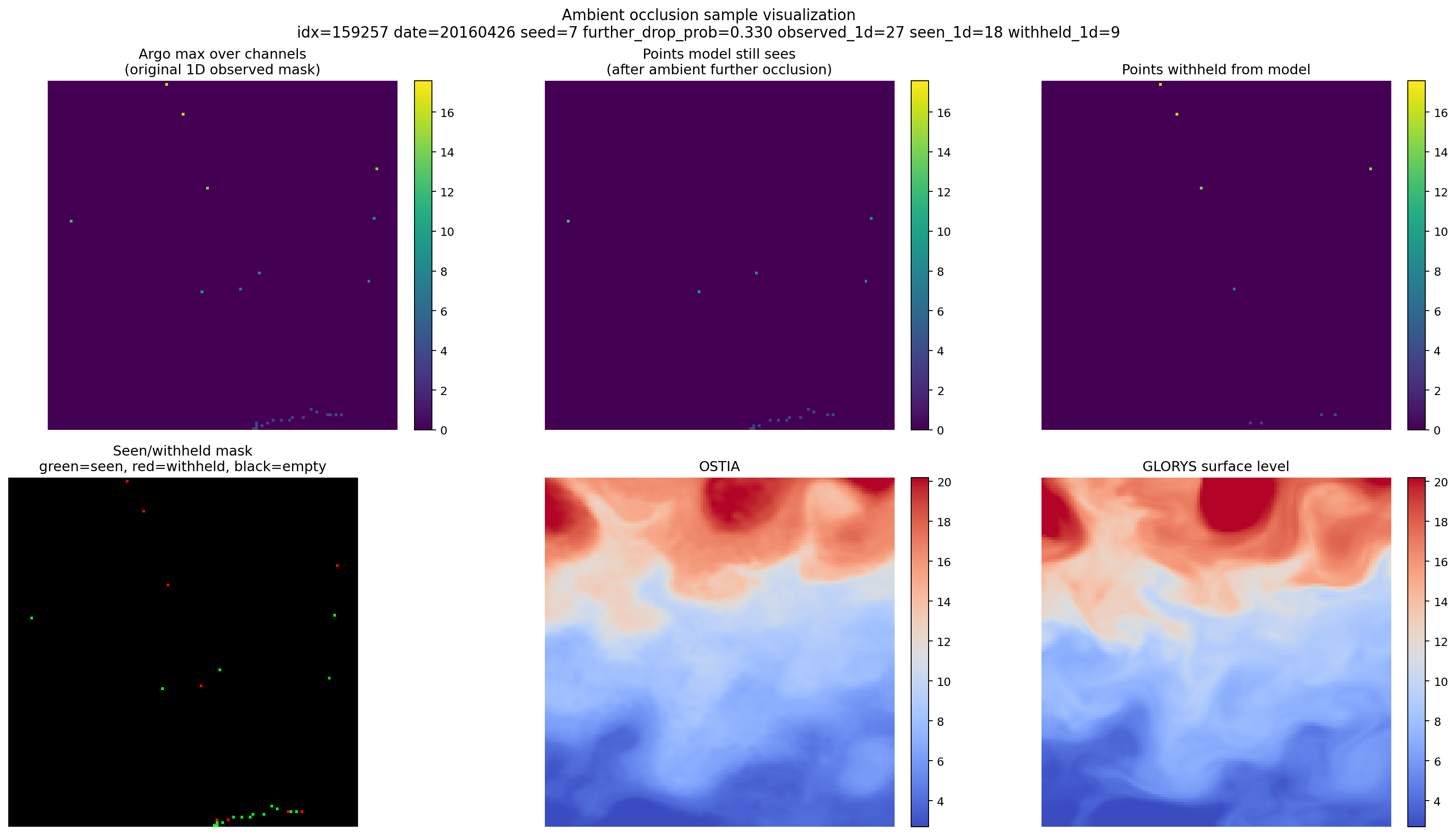
This figure shows one real training sample and the exact split that ambient occlusion creates between observations the model still receives and observations that are temporarily hidden from it.
From left to right, top to bottom:
- Argo max over channels: the original sparse Argo observations in the patch, collapsed across depth so the observed track pattern is easy to see.
- Points model still sees: the subset of those Argo observations that remains after the extra ambient masking step. These are the measurements still available to the model as input.
- Points withheld from model: the Argo observations that were originally present in the sample but were removed by the extra ambient masking step.
- Seen/withheld mask: the same split shown as a categorical mask, with green for pixels the model still sees, red for pixels withheld from the model, and black for locations with no Argo observation in the first place.
- OSTIA: the surface conditioning field for the same patch.
- GLORYS surface level: the target ocean field at the shallowest GLORYS level for the same patch, plotted on the same blue-to-red color scale as OSTIA.
What matters in this figure is the contrast between panels 1, 2, and 3: ambient occlusion does not invent a new sampling pattern from scratch. It starts from the real sparse Argo observations already present in the dataset, then removes an additional subset of them so the model has to work from a stricter, harder version of the same sample.
1. Top-Level Perspective¶
DepthDif previously trained a conditional diffusion model with a single corruption stage (dataset occlusion mask) and (typically) a loss focused on missing pixels.
The new procedure adds a second stochastic corruption stage during training:
- Start from the original observation mask \(A\) (from
x_valid_mask). - Sample an additional random keep/drop operator \(B\).
- Form a further-corrupted mask \(\tilde{A} = B \odot A\).
- Feed the model condition built from \(\tilde{A}\)-corrupted input.
- Supervise the prediction on the ambient support mask \(S = A \odot Y \odot G\), where \(A\) is
x_valid_mask, \(Y\) isy_valid_mask, and \(G\) is the GLORYS-derivedland_mask.
Intuition: the model is forced to reconstruct original observed x values from a stricter subset of those same observations.
2. Notation¶
For one sample:
- \(x_0 \in \mathbb{R}^{C \times H \times W}\): clean diffusion target (in ambient mode in this repo: normalized
x). - \(A \in \{0,1\}^{C \times H \times W}\): original validity/observation mask (
x_valid_mask). - \(G \in \{0,1\}^{1 \times H \times W}\): GLORYS spatial ocean/domain support (
land_mask). - \(x = A \odot x_0\): original sparse observed input (in this repo,
xalready carries this structure). - \(t \sim \mathrm{Unif}\{0,\dots,T-1\}\): diffusion timestep.
- \(x_t = \sqrt{\bar{\alpha}_t}\,x_0 + \sqrt{1-\bar{\alpha}_t}\,\epsilon,\ \epsilon\sim\mathcal{N}(0,I)\): noisy target branch sample.
- \(B \in \{0,1\}^{C \times H \times W}\): further keep mask sampled with keep-probability \(1-\delta\) on observed entries.
- \(\tilde{A} = B \odot A\): further-corrupted observation mask.
In implementation, \(\delta =\) model.ambient_occlusion.further_drop_prob.
3. Previous Objective (Repository Before This Change)¶
With mask_loss_with_valid_pixels=true, the loss was computed on missing pixels:
where:
- \(\hat{x}_{\theta}\) is the denoiser output.
- \(\text{target}_t = x_0\) for
parameterization="x0"or \(\epsilon\) forparameterization="epsilon".
Conditioning used the original sparse input/mask pair \((x, A)\) (plus EO, if enabled), without extra stochastic masking during training.
4. New Ambient Objective¶
4.1 Training Inputs¶
Define:
The model condition is built from \((\tilde{x}, \tilde{A}, \text{EO})\) instead of \((x, A, \text{EO})\).
Optionally (enabled by default), the noisy branch is also masked:
4.2 Loss Region and Target¶
The implemented ambient mode uses the degraded input target x, and supervises it only where the input and target supports both make sense. The ambient supervision mask is:
where \(A\) is x_valid_mask, \(Y\) is y_valid_mask, and \(G\) is the GLORYS-derived land_mask. This means ambient supervision stays on valid observed ARGO pixels inside the GLORYS ocean/domain support after degradation.
The common on-disk mask does not change diffusion loss support. The implemented loss mask is the task-valid mask intersected with the GLORYS-derived land_mask; optional output_land_mask cleanup happens only in predict_step when provided by inference code.
4.3 Relation to Paper Objective¶
The procedure matches the paper’s core structure:
up to the repository’s existing normalization/parameterization conventions and per-mask normalization by mask cardinality. In this repository, that clean target is the original sparse-observation tensor x for ambient mode, while the standard non-ambient path continues to target y.
5. What Changed vs What Stayed the Same¶
Changed¶
- Two-stage masking during training (\(A \rightarrow \tilde{A}\)).
- Condition path uses \(\tilde{A}\) and \(\tilde{x}\).
- Diffusion target switches to original
xin ambient mode. - Loss region switches to the valid ambient support mask \(A \odot Y \odot G\) in ambient mode.
- New ambient metrics are logged:
train/ambient_further_drop_fractiontrain/ambient_observed_fraction_originaltrain/ambient_observed_fraction_further- same keys under
val/*.
Unchanged¶
- Inference/sampler algorithms (DDPM/DDIM) are unchanged.
- Dataset generation of original corruption mask \(A\) is unchanged.
- The dataset returns
land_maskas GLORYS spatial support for conditioning/loss; inference code may passoutput_land_maskas common on-disk cleanup support for final predictions. - If ambient mode is disabled, the model and samplers stay the same while the objective reverts to direct
yreconstruction overy_valid_mask.
6. Implemented Safety and Constraints¶
- Parameterization guard: if ambient mode is enabled and
require_x0_parameterization=true, thenparameterizationmust be"x0"; otherwise construction raisesValueError. - Mask monotonicity: \(\tilde{A} \le A\) elementwise by construction.
- Degeneracy guard: at least
min_kept_observed_pixelsare kept per sample when possible, preventing empty effective supervision from the further corruption stage. shared_spatial_mask=trueenforces one spatial \(B\) per sample, broadcast across channels.
7. Code Mapping (Equation to Implementation)¶
- Ambient config surface:
src/depth_recon/configs/px_space/training_super_config.yaml(model.ambient_occlusion.*)- Runtime config wiring and safety:
src/depth_recon/models/diffusion/PixelDiffusion.pyPixelDiffusionConditional.from_config(...)PixelDiffusionConditional.__init__(...)
- \(\tilde{A}\) construction:
PixelDiffusionConditional._build_ambient_further_valid_mask(...)- Condition path replacement \((x,A)\to(\tilde{x},\tilde{A})\) :
training_step(...),validation_step(...)- Ambient loss execution:
src/depth_recon/models/diffusion/DenoisingDiffusionProcess/DenoisingDiffusionProcess.pyDenoisingDiffusionConditionalProcess.p_loss(...)- ambient loss mask =
x_valid_maskintersected withy_valid_maskand GLORYSland_mask - optional
apply_further_corruption_to_noisy_branch
8. Practical Interpretation¶
The old setup primarily asked the model to reconstruct hidden regions given fixed observed context.
The new setup introduces random context removal during training while preserving supervision on the original observed support. This makes the learning problem closer to the ambient objective: robustly estimate clean content under stochastic measurement degradation, not only under one fixed missingness pattern per sample.