Data¶
DepthDif uses monthly ocean reanalysis tiles and converts them into fixed-size patch tensors for fast training.
Source Data¶
The current workflow is built around the Copernicus Marine Global Ocean Physics Reanalysis product.
- Time span used in this project: 2000-2025
- Typical patch size:
128 x 128 - Spatial resolution context in README:
1/12° - Sparse-observation behavior is simulated by synthetic masking
Reference dataset link: Global Ocean Physics Reanalysis
Example CLI from README:
copernicusmarine get -i cmems_mod_glo_phy_my_0.083deg_P1M-m --filter "*2021/*"
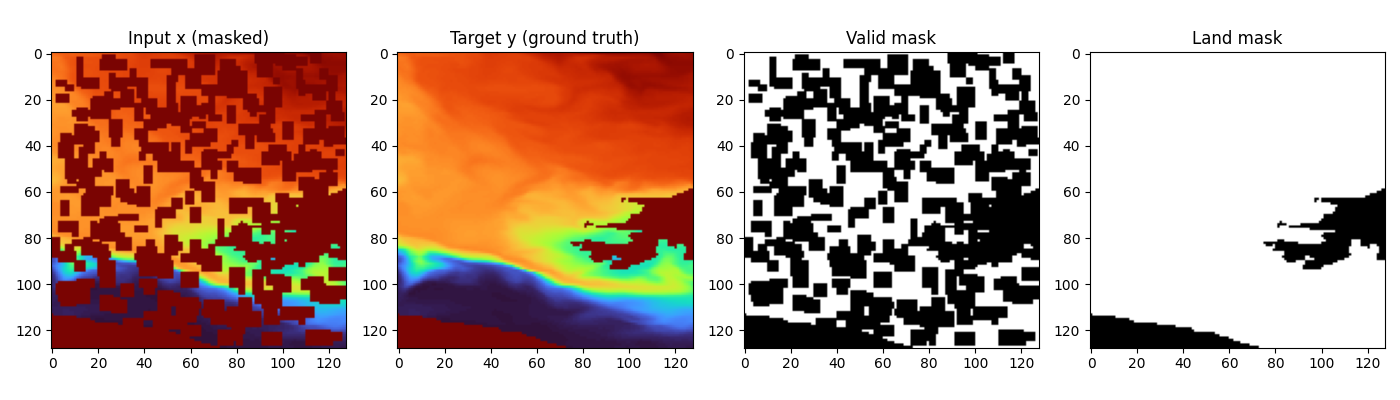
Dataset example for 50% occlusion:
On-Disk Export Format¶
The data export script is data/dataset_to_disk.py.
Core behavior:
- reads *.nc files from dataset.root_dir
- extracts requested depth bands from one variable (default thetao)
- writes each patch to y_npy/<sample_id>.npy
- writes an index CSV with paths and metadata (patch_index_with_paths.csv)
- can enforce nodata filtering via max_nodata_fraction
- assigns a split column (train/val) during export
For EO + 3 deeper-band training, the 4-band layout is expected as: - channel 0: EO/surface condition - channels 1..3: deeper temperature target bands
Implemented Dataset Variants¶
Variant selection is resolved from dataset.dataset_variant in data config.
1) temp_v1 (single-band)¶
SurfaceTempPatchLightDataset (data/dataset_temp_v1.py) returns:
- x: corrupted input (same channels as y, after masking)
- y: clean target
- valid_mask: valid/known pixels mask
- land_mask: ocean/land validity mask
- date: parsed integer date (YYYYMMDD)
- optional: coords, info
2) eo_4band (EO-conditioned multiband)¶
SurfaceTempPatch4BandsLightDataset (data/dataset_4bands.py) returns:
- eo: channel 0 condition
- x: corrupted deeper channels (channels 1..3)
- y: clean deeper channels (channels 1..3)
- valid_mask: per-channel validity mask for y
- land_mask: per-channel land/ocean mask
- date: parsed integer date (YYYYMMDD)
- optional: coords, info
EO + multiband example:

Masking, Validity, and Augmentation¶
Normalization and units¶
Temperature tensors are loaded in degrees Celsius and normalized through utils.normalizations.temperature_normalize:
- norm: convert Celsius to Kelvin (T_K = T_C + 273.15), then apply Z-score with dataset stats (Y_MEAN=289.74267177946783, Y_STD=10.933397487585731)
- denorm: invert Z-score in Kelvin space, then convert back to Celsius
- plotting ranges (PLOT_TEMP_MIN, PLOT_TEMP_MAX) remain defined in Celsius space
Corruption pipeline¶
Both dataset variants create sparse x by masking random rectangular patches:
- target masked coverage controlled by mask_fraction
- patch sizes from mask_patch_min to mask_patch_max
- corruption is applied spatially
- in temp_v1, corruption is effectively a single-band spatial mask
- in eo_4band, corruption is now per-band, so valid_mask semantics are fully 3D (band x H x W)
Validity and land masks¶
- masks are derived from finite-value checks and configured fill-value logic
valid_maskis used for both conditioning and masked-loss options in the modelland_maskis used to suppress land influence in masked loss and optional output post-processing- masked loss is computed over generated pixels (
1 - valid_mask), optionally ocean-gated byland_mask
EO degradation options (eo_4band)¶
If enabled in config:
- eo_random_scale_enabled: currently implemented as an additive random EO offset in [-2.0, 2.0] temperature units
- eo_speckle_noise_enabled: multiplicative speckle (1 + 0.01 * eps) clamped to [0.9, 1.1]
- eo_dropout_prob: random EO dropout by setting eo to zeros per sample
Geometric augmentation¶
When enable_transform=true, random 90° rotations/flips are applied consistently to:
- data tensors
- validity masks
- land masks
Coordinates and Date¶
When return_coords=true, dataset returns patch-center coordinates:
- latitude center: arithmetic mean of lat0 and lat1
- longitude center: dateline-safe circular midpoint from lon0 and lon1
Date parsing behavior:
- YYYYMMDD suffix in source_file -> used directly
- YYYYMM suffix -> converted to mid-month (YYYYMM15)
- invalid/missing -> fallback 19700115
Split Behavior in Current Training Runner¶
This is an important implementation detail from train.py + data/datamodule.py:
train.pycurrently builds dataset withsplit="all"- then
DepthTileDataModulecreates a seeded random split usingsplit.val_fraction - this means precomputed index
splitlabels are not automatically enforced by the current runner
If you need strict geographic window splits from index labels, use a custom train/val dataset wiring path (or adapt the runner).
Helper for writing deterministic window-level splits:
- data/assign_window_split.py